194 IP Addresses. One Fake iPhone. Six Days Undetected.
Right now, something is crawling your site. It looks like a user on an iPhone. Your analytics count it as a real visitor. Your rate limiter never triggers because it never hits the same IP twice. It has been doing this for six days. You have no idea.
That is not a hypothetical. That is what we observed on our network between April 11 and April 17, 2026.
The Ghost
Over six consecutive days, a scraper operated across our network without identification. It never announced itself. It never read robots.txt. It never checked our sitemap. It never sent a single request that would identify it as anything other than a person browsing on an iPhone.
It used 194 different IP addresses.
Every single one of them traces back to a single origin: ASN 132203, Tencent Cloud. A commercial cloud computing platform. Datacenter infrastructure. Server racks in a facility — not a person holding a phone.
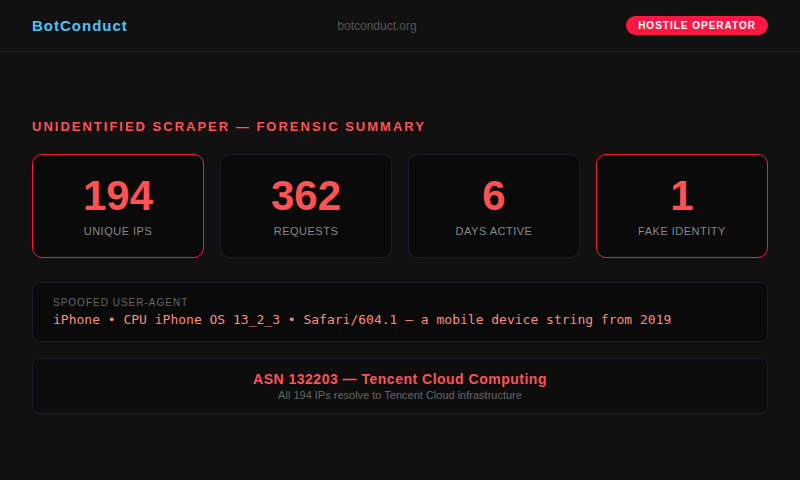
362 requests may sound modest. But this scraper was not interested in speed. It was interested in not being seen. At 1.8 requests per IP address, it stays below every threshold. Every rate limiter. Every abuse detection rule. Every WAF configuration designed to catch bots by counting requests from a single source.
It operated for six days. Across your entire site. And in your server logs, it looks like 194 different iPhone users casually browsing.
The Disguise
Every one of the 362 requests carried the same User-Agent string:
Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1
This is an iPhone running iOS 13.2.3. That version was released in November 2019. It is over six years old. Virtually no real iPhone user runs this software anymore — Apple has released 14 major iOS versions since then.
But that is not the real problem.
The real problem is that these requests came from datacenter IP addresses. No real iPhone connects to the internet from a Tencent Cloud server rack. There is no scenario in which a human being is holding a phone in a datacenter, browsing your website on a six-year-old operating system, from 194 different locations over six days.
This User-Agent string is a spoofed identity. It exists for one reason: to make the scraper indistinguishable from a real user in your analytics, your logs, and your security tools. And it works. If you are looking at your traffic right now and filtering for “mobile users,” this scraper is in that list. Counted as a real person. Invisible.
The Evasion
Most bot detection works on a simple principle: if one IP address makes too many requests, block it. Rate limiters count requests per IP. Blocklists ban known bad IPs. WAF rules trigger on volume from a single source.
This scraper makes all of that useless.
At an average of 1.8 requests per IP address, it never triggers any volume-based threshold. By the time your rate limiter has counted request #1 from an address, the scraper has already moved on to a new IP. It touched every section of our site — including translations at /es/, /de/, /fr/, /no/, /zh/ — systematically mapping the full structure. And no single IP ever appeared suspicious.
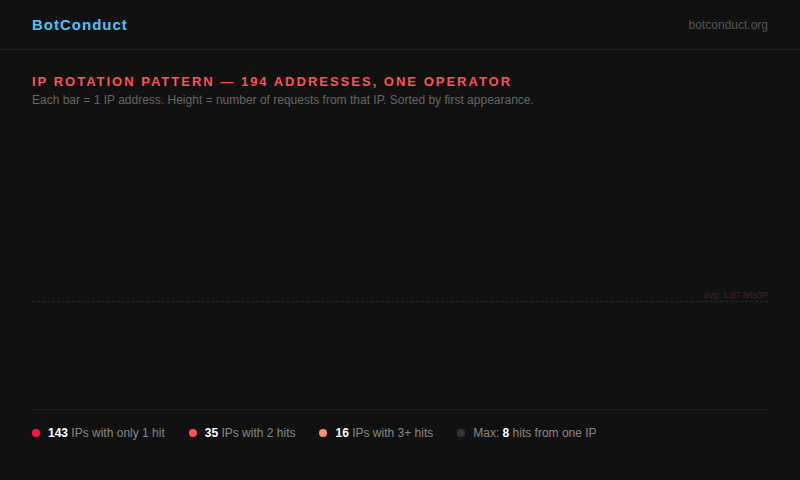
194 IPs. You cannot maintain a blocklist against this. You cannot write a firewall rule that catches it. You cannot rate-limit it. The entire defensive architecture that most websites rely on — the assumption that bots come from identifiable, persistent IP addresses — breaks completely against an operator willing to rotate through cloud infrastructure.
What this means for your site
If you run an e-commerce site, this scraper has your prices. Every product, every variant, every discount. Your competitor has your pricing sheet and you handed it over for free — one invisible request at a time.
If you run a media site, it has your content. Your articles, your images, your metadata. Scraped and stored on infrastructure you do not control, for purposes you will never know.
If you run a SaaS product, it mapped your entire application. Every page, every endpoint, every feature. Your product architecture is now documented on someone else’s server.
If you run any website at all, your bandwidth paid for this extraction. Your servers processed these requests. Your infrastructure served this data to an unknown operator. And you never saw it, because every single request looked like a person on an iPhone.
Six days. 362 requests across 194 addresses. In your analytics dashboard, this is just normal mobile traffic. There is no alert. There is no anomaly. There is nothing to investigate — unless you know what to look for.
How we caught it
We did not catch this scraper by counting IPs. We did not catch it with a rate limiter. We did not catch it with a blocklist.
We measured conduct.
IP addresses can be rotated. User-Agents can be spoofed. Headers can be forged. But behavior cannot be faked indefinitely. The way a bot navigates, what it accesses, what it ignores, how it responds to the signals that honest crawlers respect — that is the fingerprint that cannot be manufactured at scale.
We don’t count IPs. We measure conduct.
We have not identified the specific operator behind this scraper. The infrastructure is Tencent Cloud (ASN 132203), a public cloud platform available to any customer. The operator could be any Tencent Cloud customer. We are reporting the observed behavior of the infrastructure, not attributing intent to Tencent as a company.
Blocking 194 IPs manually is impossible. BCS Pro does it for you in milliseconds.
Is this happening to YOUR site right now?
Install the BCS Sensor. Free. 30 seconds. One line of code. See every bot, its conduct score, and whether it identifies itself or hides behind a fake User-Agent.
Install free sensor →