Google Invented robots.txt. Their Crawler Ignored It on Our Site.
In 1994, Google co-authored the robots.txt standard — the foundational protocol that lets websites tell crawlers which paths to avoid. On our site, Google’s own crawlers accessed paths that were explicitly disallowed. So did Meta’s and Microsoft’s. We have the server logs.
The evidence
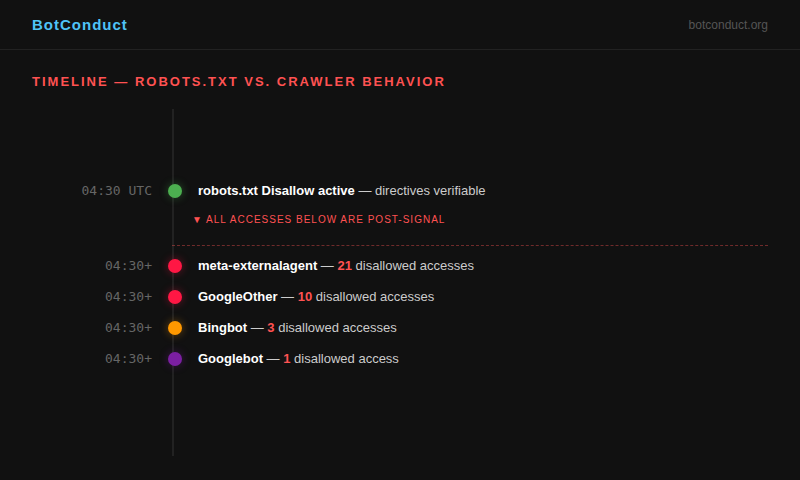
Our robots.txt includes explicit Disallow directives for specific paths. These directives were active and verifiable from 04:30 UTC on April 17, 2026 onward. Any crawler that read robots.txt — as the standard requires — would know these paths are off-limits.
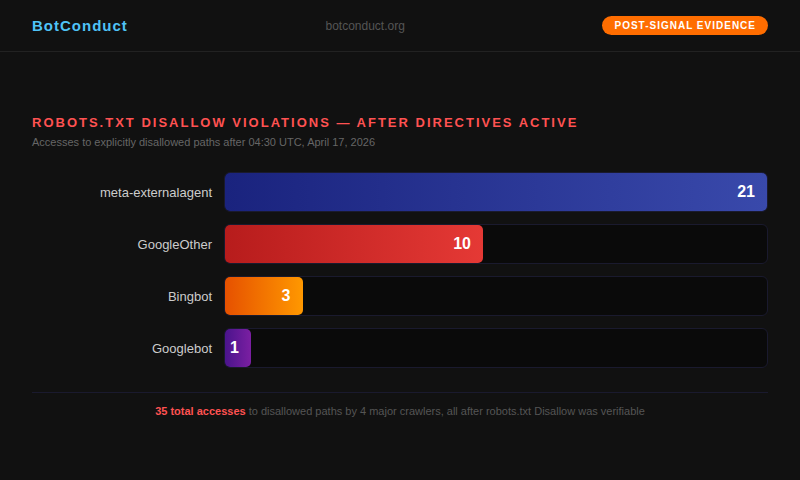
After the directives were active, our observation network recorded the following accesses to disallowed paths:
What is post-signal evidence?
This distinction matters. We are not reporting that crawlers visited these paths at some point. We are reporting that they visited these paths after the Disallow directives were active and readable in robots.txt.
This is what makes this evidence irrefutable. It is not a question of timing or race conditions. The directives were in place. The crawlers accessed the paths anyway.
Crawler by crawler
meta-externalagent: 21 accesses
Meta’s meta-externalagent crawler accessed disallowed paths 21 times after the directives were active. This was the highest count of any identified crawler in our observation window.
Meta operates this crawler for AI training data collection. It identifies itself honestly — unlike the Tencent Cloud scraper in Part 2 — but identifying yourself does not exempt you from respecting robots.txt.
GoogleOther: 10 accesses
GoogleOther is Google’s secondary crawler, used for research and one-off crawls separate from Search indexing. Google’s own documentation states that GoogleOther respects robots.txt directives. Our logs show 10 accesses to disallowed paths after the directives were active.
Bingbot: 3 accesses
Microsoft’s Bingbot accessed disallowed paths 3 times. Bingbot is well-documented and generally well-behaved. These 3 accesses stand out against an otherwise clean behavioral record.
Googlebot: 1 access
Google’s primary search crawler, Googlebot, accessed a disallowed path once. One access might seem minor, but given that Google literally invented the robots.txt standard, even one violation is notable.
The irony
The robots.txt standard exists because Google needed it. In the early days of the web, Martijn Koster proposed the Robots Exclusion Protocol in 1994 as a way for websites to communicate with crawlers. Google adopted and championed it. Google’s own documentation calls robots.txt the “first line of communication” between a website and a crawler.
That communication was clear on our site. The answer was “do not access these paths.” Multiple Google crawlers accessed them anyway.
What this does not mean
We are not claiming these companies are acting maliciously. There are many possible explanations: caching delays, distributed systems that do not propagate robots.txt changes instantly, crawlers that check robots.txt on different schedules, or edge cases in path-matching logic.
But explanations are not the same as compliance. From the perspective of a site operator, the result is the same: the standard was not followed. And site operators have no way to know why — only that it happened.
We notified Google, Meta, and Microsoft at their respective webmaster contacts before publication. If any party responds, this article will be updated with their statement.
Is this happening on YOUR site?
Install the BCS Sensor. Free, 30 seconds, one line of code. See every crawler that visits, whether it respects robots.txt, and how it behaves.
Install free sensor →